最新的AGI理论:“加强GPT
栏目:公司资讯 发布时间:2025-07-17 10:47
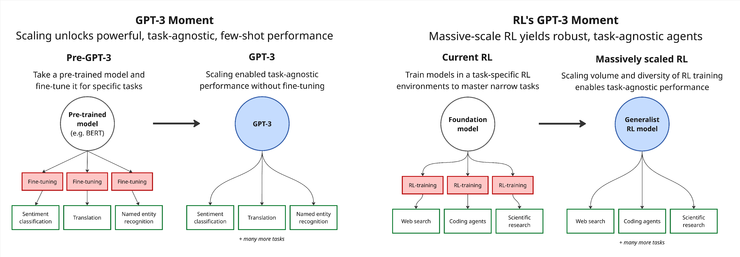 最近,三位机械化的创始人,一个外国的AI开始,他们加入了一篇文章以做出勇敢的判断:RL可能具有“ GPT-3时刻”,但仍然需要接受相当于数千到数千年的“用于模型处理任务的时间”的培训。他们认为,当前的RL模型仍然存在明显的缺点,例如,一般能力和适应新任务的困难。这种情况确实与GPT -3出现之前的语言模型相似 - 它可以解决特定的问题,但是很难移动和扩展。为了解决这个问题,他们提出了一种称为“复制培训”的新培训范式:让该模型模拟在虚拟环境中操作真实软件的过程,例如使用浏览器,代码编写,处理行任务等。但是他们认为,复制培训是一条重要的道路E RL模型用于通用智能,并有望带来像GPT-3这样的跳跃能力。总而言之,Leifeng.com AI技术评论进行了分类并显示了原始文本而没有更改其原始含义:当RL符合GPT-3型大型GPT-3时,我们向我们展示了一个基本事实:仅通过提高规模,它就可以产生强大的,不符合任务的射击功能,甚至更多,甚至更多,甚至更多,甚至更多,甚至更多,甚至更加偶尔。活动。在此之前,为了在特定任务中实现Pinadelious的性能,通常有必要对大规模的通用语料库进行预训练,然后进行对目标任务进行细调。当今的强化学习(RL)仍在GPT-3出现之前仍在舞台上:我们仍然先训练大型模型,然后在某些专业环境中进行乏味的工作水平维修水平。但是这种方法具有基本缺陷 - 其概括的能力非常脆弱。当面对M的环境奥德尔(Odel)略有变化,性能迅速崩溃。我们相信RL也会激励“ GPT-3时刻”。这意味着培训方法将从微调到某些环境再到大规模培训,再到成千上万的不同环境,以培养射击能力很小的射击和预防性任务,这些任务很容易响应新任务。但是,为了实现这一跳转,只有开发具有尺寸和差异的训练环境(大于当前水平),这是将RL推向能力爆炸的关键。实施GPT-3级培训需要多少?但是,当前的RL大小仍然非常有限。以DeepSeek-R1为例,其培训数据包含近600,000个数学问题。认为人们平均需要5分钟才能完成每个问题,因此一般的同等产品大约是不断制造的6年。相反,如果计算GPT-3使用的3000亿代币语料库b按照人们写作的正常速度,将需要数十万年的时间,并且数量级远非同一级别。另一方面,如果您希望RL投资于当前最切近的假装模型的计算能力,则可能需要大约10,000年的人工工作时间(即模型处理所需的时间,转换为人们完成相同任务所需的时间)。 DeepSeek-R1在RL相中使用了大约6e23 flop,这与大约6年的模型处理时间一致。如果随后的培训保持与DeepSeek-R1相似的训练周期和水平,那么训练量表将增加到6E26失败水平,几乎与近6000年的模型处理任务一致。当然,随着差异的增加 - 任务各不相同,仍然无法确定RL是否会在将来加强差异或较小的批次大小,或增加麻木将来将来的练习。由于缺乏礼节经验数据,仍然很难准确评估模型的所需模型时间,但是“ 10,000年”可能是合理的估计水平。为了易于理解,我们可以将该培训量表与工程学的一些主要项目进行比较:如果是Windows Server 2008,GTA V或Red Hat Linux 7.1,则估计它们将需要将近10,000年的人工劳动。值得一提的是,从经济角度来看,在此规模上扩大RL培训是可能的。由于计算能力支出占主导地位的整体培训成本,因此将RL培训预算提高到与语言模型的预培训相当的水平,预计Maputi会显着执行该模型的绩效,而不会导致总成本的指数增长。真正的挑战是如何构建多样化的RL环境,可以自动评估。为了实现这一目标,也许我们需要完全重新构想INE RL环境的设计和构建。培训或复制解决方案?想象一下,如果您每次训练下一个预测(随后的预测)时需要手动编写完整的培训语料库,几乎不可能完成。实际上,我们才能训练强大的语言模型的原因是因为我们可以直接使用大量现有的内容来源,例如书籍,学术论文,博客文章和Reddit讨论来生成大规模的优质培训数据。同样,我们认为,预计PAG学生将以自己的GPT-3时刻提供,并且实现它的关键可能是我们称为“复制培训”的新范式。主要想法是:让AI模型重现现有的软件产品或某些特定操作。在舞台开始时,您可以从命令行中的一些相对简单的工具开始,例如实现某种类型的哈希或加密算法的迷你程序RITHM-这些愿望清晰,紧凑,适合早期培训。随着模型的功能的提高,复制培训的范围也可以扩展到更复杂的系统,例如Web应用程序,专业软件甚至大型游戏。 leifeng.com(公共帐户:leifeng.com)每个副本练习任务将提供详细的绩效规格和YETREFERCE-实施。 AI模型的工作是生成与对行为的引用实现完全一致的版本。该方法的最大优点是审查是非常直接和客观的:模型的输出与参考结果完全一致,要么不一致。明确的评分标准极大地简化了训练过程中的检查机制,并提高了训练效率。尽管“复制培训”任务的形式可能与Sunny软件开发不同,但它们针对的是当前AI的一些主要链接系统仍然容易受到工程能力的影响。例如,为了使该模型复制复杂的算法(例如已经存在的案例,并且包含数千行代码和严格遵守详细规范的命令的命令行,必须具有以下基本功能:阅读并深入了解复杂的技术文档;严格按照规格执行说明,以防止逻辑或实施中的任何偏差;能够识别和解决早期错误,并具有可靠的问题恢复能力;在长期和高复杂的活动中保持稳定的产量,例如构成数周的人类工程师,结果的质量直接通过准确性来衡量;面对困难,请弹性,并且不容易对“几乎还可以”的半生产产品满意。这些功能的结合是开发可靠,质量AI工程系统的基础多发性硬化症。 “复制训练”的独特价值在于一个事实,即通过减少高强度的真正复杂系统,它为模型提供了系统地磨练上述功能的途径。这不仅为当前AI系统的功能发展,而且为培训一般目标代理的培训奠定了重要的技术基础。我们预测,“复制培训”将是AI培训的下一个主要范式。这种判断源自当前AI开发的基本趋势:通过大量现有的人类创建数据,自动构建了一项丰富的新任务。由于自然语言来源在互联网上广泛存在,因此该软件本身是一种结构性高度且已准备好制作的材料。复制培训是基于该奖项的,该奖项证明了一种有效制作复杂任务的测量和自动方法,并促使我们凭借端到端的开发能力迁移到AI,可以独立完成的代理e整个软件项目。当然,这种方法并非没有挑战。例如,如何编写既好又全面的试验是工程学的主要问题,并且通常需要很多制造商。此外,就形式而言,复制培训略有“人造” - 在软件的太阳开发中,完全复制现有软件的情况并不少见,尽管它在软件传输,重建传统系统和“清洁室”重新创作之类的方案中具有。但是,我们认为,复制培训提供了清晰的RL培训环境,可以达到支持能力所需的巨大规模。这种范式可能是RL“ GPT-3时刻”的关键 - 这有助于该模型积累数千年的任务体验,从而具有稳定的独立工作技能。那么,培训是否是实施“完全自动制造”的最终途径?我们不这么认为。虽然有望根据可以根据详细的设计说明独立完成复杂的软件项目的系统来诞生,但这种系统仍然缺乏开放性,人们拥有的灵活性以及在跨域情景中抽象计划和高级管理的能力。尽管AI将来已成为领先的程序员,但他们可能无法从更广泛的意义上执行制造和协调任务。但是,我们认为,复制培训仍然可以成为下一个培训范式的主要“桥梁”,因为我们必须在复制培训之前进行预训练。我们对这种新范式的潜力和前景充满期望
最近,三位机械化的创始人,一个外国的AI开始,他们加入了一篇文章以做出勇敢的判断:RL可能具有“ GPT-3时刻”,但仍然需要接受相当于数千到数千年的“用于模型处理任务的时间”的培训。他们认为,当前的RL模型仍然存在明显的缺点,例如,一般能力和适应新任务的困难。这种情况确实与GPT -3出现之前的语言模型相似 - 它可以解决特定的问题,但是很难移动和扩展。为了解决这个问题,他们提出了一种称为“复制培训”的新培训范式:让该模型模拟在虚拟环境中操作真实软件的过程,例如使用浏览器,代码编写,处理行任务等。但是他们认为,复制培训是一条重要的道路E RL模型用于通用智能,并有望带来像GPT-3这样的跳跃能力。总而言之,Leifeng.com AI技术评论进行了分类并显示了原始文本而没有更改其原始含义:当RL符合GPT-3型大型GPT-3时,我们向我们展示了一个基本事实:仅通过提高规模,它就可以产生强大的,不符合任务的射击功能,甚至更多,甚至更多,甚至更多,甚至更多,甚至更多,甚至更加偶尔。活动。在此之前,为了在特定任务中实现Pinadelious的性能,通常有必要对大规模的通用语料库进行预训练,然后进行对目标任务进行细调。当今的强化学习(RL)仍在GPT-3出现之前仍在舞台上:我们仍然先训练大型模型,然后在某些专业环境中进行乏味的工作水平维修水平。但是这种方法具有基本缺陷 - 其概括的能力非常脆弱。当面对M的环境奥德尔(Odel)略有变化,性能迅速崩溃。我们相信RL也会激励“ GPT-3时刻”。这意味着培训方法将从微调到某些环境再到大规模培训,再到成千上万的不同环境,以培养射击能力很小的射击和预防性任务,这些任务很容易响应新任务。但是,为了实现这一跳转,只有开发具有尺寸和差异的训练环境(大于当前水平),这是将RL推向能力爆炸的关键。实施GPT-3级培训需要多少?但是,当前的RL大小仍然非常有限。以DeepSeek-R1为例,其培训数据包含近600,000个数学问题。认为人们平均需要5分钟才能完成每个问题,因此一般的同等产品大约是不断制造的6年。相反,如果计算GPT-3使用的3000亿代币语料库b按照人们写作的正常速度,将需要数十万年的时间,并且数量级远非同一级别。另一方面,如果您希望RL投资于当前最切近的假装模型的计算能力,则可能需要大约10,000年的人工工作时间(即模型处理所需的时间,转换为人们完成相同任务所需的时间)。 DeepSeek-R1在RL相中使用了大约6e23 flop,这与大约6年的模型处理时间一致。如果随后的培训保持与DeepSeek-R1相似的训练周期和水平,那么训练量表将增加到6E26失败水平,几乎与近6000年的模型处理任务一致。当然,随着差异的增加 - 任务各不相同,仍然无法确定RL是否会在将来加强差异或较小的批次大小,或增加麻木将来将来的练习。由于缺乏礼节经验数据,仍然很难准确评估模型的所需模型时间,但是“ 10,000年”可能是合理的估计水平。为了易于理解,我们可以将该培训量表与工程学的一些主要项目进行比较:如果是Windows Server 2008,GTA V或Red Hat Linux 7.1,则估计它们将需要将近10,000年的人工劳动。值得一提的是,从经济角度来看,在此规模上扩大RL培训是可能的。由于计算能力支出占主导地位的整体培训成本,因此将RL培训预算提高到与语言模型的预培训相当的水平,预计Maputi会显着执行该模型的绩效,而不会导致总成本的指数增长。真正的挑战是如何构建多样化的RL环境,可以自动评估。为了实现这一目标,也许我们需要完全重新构想INE RL环境的设计和构建。培训或复制解决方案?想象一下,如果您每次训练下一个预测(随后的预测)时需要手动编写完整的培训语料库,几乎不可能完成。实际上,我们才能训练强大的语言模型的原因是因为我们可以直接使用大量现有的内容来源,例如书籍,学术论文,博客文章和Reddit讨论来生成大规模的优质培训数据。同样,我们认为,预计PAG学生将以自己的GPT-3时刻提供,并且实现它的关键可能是我们称为“复制培训”的新范式。主要想法是:让AI模型重现现有的软件产品或某些特定操作。在舞台开始时,您可以从命令行中的一些相对简单的工具开始,例如实现某种类型的哈希或加密算法的迷你程序RITHM-这些愿望清晰,紧凑,适合早期培训。随着模型的功能的提高,复制培训的范围也可以扩展到更复杂的系统,例如Web应用程序,专业软件甚至大型游戏。 leifeng.com(公共帐户:leifeng.com)每个副本练习任务将提供详细的绩效规格和YETREFERCE-实施。 AI模型的工作是生成与对行为的引用实现完全一致的版本。该方法的最大优点是审查是非常直接和客观的:模型的输出与参考结果完全一致,要么不一致。明确的评分标准极大地简化了训练过程中的检查机制,并提高了训练效率。尽管“复制培训”任务的形式可能与Sunny软件开发不同,但它们针对的是当前AI的一些主要链接系统仍然容易受到工程能力的影响。例如,为了使该模型复制复杂的算法(例如已经存在的案例,并且包含数千行代码和严格遵守详细规范的命令的命令行,必须具有以下基本功能:阅读并深入了解复杂的技术文档;严格按照规格执行说明,以防止逻辑或实施中的任何偏差;能够识别和解决早期错误,并具有可靠的问题恢复能力;在长期和高复杂的活动中保持稳定的产量,例如构成数周的人类工程师,结果的质量直接通过准确性来衡量;面对困难,请弹性,并且不容易对“几乎还可以”的半生产产品满意。这些功能的结合是开发可靠,质量AI工程系统的基础多发性硬化症。 “复制训练”的独特价值在于一个事实,即通过减少高强度的真正复杂系统,它为模型提供了系统地磨练上述功能的途径。这不仅为当前AI系统的功能发展,而且为培训一般目标代理的培训奠定了重要的技术基础。我们预测,“复制培训”将是AI培训的下一个主要范式。这种判断源自当前AI开发的基本趋势:通过大量现有的人类创建数据,自动构建了一项丰富的新任务。由于自然语言来源在互联网上广泛存在,因此该软件本身是一种结构性高度且已准备好制作的材料。复制培训是基于该奖项的,该奖项证明了一种有效制作复杂任务的测量和自动方法,并促使我们凭借端到端的开发能力迁移到AI,可以独立完成的代理e整个软件项目。当然,这种方法并非没有挑战。例如,如何编写既好又全面的试验是工程学的主要问题,并且通常需要很多制造商。此外,就形式而言,复制培训略有“人造” - 在软件的太阳开发中,完全复制现有软件的情况并不少见,尽管它在软件传输,重建传统系统和“清洁室”重新创作之类的方案中具有。但是,我们认为,复制培训提供了清晰的RL培训环境,可以达到支持能力所需的巨大规模。这种范式可能是RL“ GPT-3时刻”的关键 - 这有助于该模型积累数千年的任务体验,从而具有稳定的独立工作技能。那么,培训是否是实施“完全自动制造”的最终途径?我们不这么认为。虽然有望根据可以根据详细的设计说明独立完成复杂的软件项目的系统来诞生,但这种系统仍然缺乏开放性,人们拥有的灵活性以及在跨域情景中抽象计划和高级管理的能力。尽管AI将来已成为领先的程序员,但他们可能无法从更广泛的意义上执行制造和协调任务。但是,我们认为,复制培训仍然可以成为下一个培训范式的主要“桥梁”,因为我们必须在复制培训之前进行预训练。我们对这种新范式的潜力和前景充满期望